
Python勉強中で備忘録です。今回は解説の理解が難しいものがあり、さらに問題が多数あり、かなり時間がかかりました。

⇒これ単独ではwordが定義されていないのでエラーが出る。以下を先に入れておく必要がある。
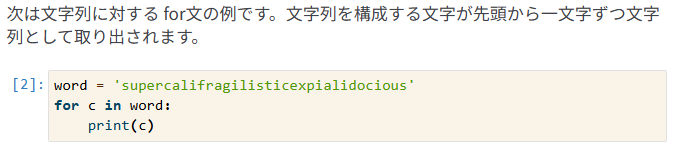

⇒[7]と[9]の式の違いが良く分からない。出力のデータで、valueの前のカンマの有無の差はあるが。ChatGPTの解答は以下の通り。
① for key in dic1:
dic1 = {'cat': 3, 'dog': 3, 'elephant': 8}
for key in dic1:
print('key:', key, ', value:', dic1[key])
- ループ変数
keyには キーだけ が順に入ります。 - 値 (
value) を使いたいときは、dic1[key]として改めて辞書から取り出す必要があります。
👉 この場合のイテレーション対象は dic1.keys() と同じです。
② for key, value in dic1.items():
dic1 = {'cat': 3, 'dog': 3, 'elephant': 8}
for key, value in dic1.items():
print('key:', key, 'value:', value)
dic1.items()は (キー, 値) のタプル のリスト風オブジェクトを返します。
例:[('cat', 3), ('dog', 3), ('elephant', 8)]- ループでタプルを展開して、
keyとvalueにそれぞれ代入できます。 - 値を取り出すのに
dic1[key]と書く必要がなく、コードがすっきりします。
✅ 違いまとめ
for key in dic1:→ キーだけ取り出す。値はdic1[key]で参照。for key, value in dic1.items():→ キーと値を同時に取り出せる。
実用上は、キーと値の両方を使うときは .items() を使う方が読みやすい です。
一方で、キーだけを使いたいときは for key in dic1: の方がシンプルです。
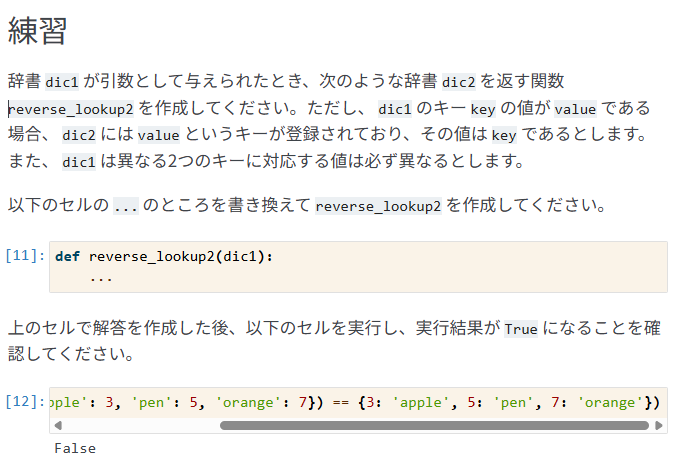
⇒以下の解答を作成したが間違い。ChatGPTの添削は以下の通り。完全に納得。
def reverse_lookup2(dic1):
for key, value in dic1.items():
dic2 = {}
dic2[value] = key
return dic2
なるほど!問題文の条件とコードを照らし合わせると、「辞書をループするたびに dic2 を初期化している」ことが一番の問題です。
あなたのコードを追ってみると:
def reverse_lookup2(dic1):
for key, value in dic1.items():
dic2 = {} # ← ループごとに毎回リセットされる
dic2[value] = key # ← 1つだけ登録
return dic2 # ← すぐに返して終了
問題点
- dic2 をループ内で初期化している
→ 毎回{}からやり直しなので、最後まで回しても1個しか残らない。 returnがループの中にある
→ 最初の1回目で関数が終了してしまい、全要素を変換できない。
修正案
dic2 = {}はループの前で1度だけ作る。- 全部の要素を登録してから return する。
def reverse_lookup2(dic1):
dic2 = {}
for key, value in dic1.items():
dic2[value] = key
return dic2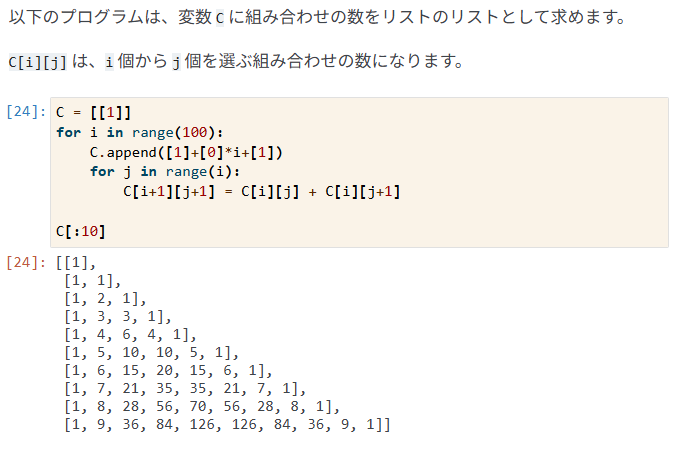
⇒ここのプログラミングの式が分からない。具体的には以下が分からない。
・C.append([1]+[0]*i+[1])によって、Cのリストに何が追加される?
・C[i+1][j+1] = C[i][j] + C[i][j+1] によって何が行われる?リストに何が追加される?
・C[:10]の「:10」はiが10までの分表示するということ?
ChatGPTの解説は以下の通り。
このコードは パスカルの三角形 をリストのリスト(2次元配列)として作成する処理です。
一行ずつ役割を見ていきましょう。
コード全体
C = [[1]]
for i in range(100):
C.append([1] + [0]*i + [1])
for j in range(i):
C[i+1][j+1] = C[i][j] + C[i][j+1]
C[:10]
1. 初期値
C = [[1]]
- まず
Cはリストのリスト。 - 1行目(0段目)として
[1]を入れておく。
例:[[1]]
2. 外側のループ
for i in range(100):
iは 今から作る行の1つ前の行のインデックス(0〜99)。- ループごとに 新しい行を作ってCに追加していく。
3. 新しい行を追加
C.append([1] + [0]*i + [1])
- 新しい行(
i+1行目)を一旦 端だけ1で中身0 で作る。 - 例えば
i=2の時は[1] + [0,0] + [1]→[1, 0, 0, 1]。 - ここで
[0]*iは0をi個並べるリスト。
4. 内側のループで値を埋める
for j in range(i):
C[i+1][j+1] = C[i][j] + C[i][j+1]
- 新しい行の中の値を前の行から計算する。
- パスカルの三角形の性質
新しい行の(j+1)番目 = 1つ上の左 + 1つ上の右 - 例えば上から3行目(i=2 → i+1=3行目)のj=0の計算:
C[3][1] = C[2][0] + C[2][1]
5. 結果の取得
C[:10]
- 最初の10行を表示。
- 出力例(先頭だけ整形して示す):
[[1],
[1, 1],
[1, 2, 1],
[1, 3, 3, 1],
[1, 4, 6, 4, 1],
...
]
これがパスカルの三角形の最初の10行です。
🔑 まとめ
Cは 二項係数を並べたパスカルの三角形。appendで新しい行を足し、- 前の行の左右の和を使って内側の数値を埋めている。
C[:10]で最初の10段分を確認しているだけです
⇒これを見ても完全には理解できず。以下に調べた内容をまとめます。
・改行されているのはpythonの表示が見易さ的に勝手にやっているだけで、実質はリストが並んでいるだけ。
・新しい行を追加というのは新しいリストを追加という方が正しい。
・C[:10]は10行というよりは10要素(10リスト)と言う方が正しい。
⇒再度ChatGPTに解説を要求。一部抜粋します。
i = 0 のとき
- ループ変数:
i = 0 - ループ開始時の C:
[[1]](行数 = 1、C[0]が存在)
C.append([1] + [0]*0 + [1])を実行[0]*0は[]だから、追加するリストは[1, 1]Cが[[1], [1, 1]]になる(新しくC[1]ができた)
for j in range(i):→range(0)は空なので 内側ループは実行されない(何も更新されない)
- i=0 終了後の C:
[[1], [1, 1]]
i = 1 のとき
- ループ変数:
i = 1 - 開始時の C:
[[1], [1,1]](C[0],C[1]がある)
C.append([1] + [0]*1 + [1])[0]*1 = [0]→ 追加するリストは[1, 0, 1]Cは[[1], [1,1], [1,0,1]](新しくC[2]ができる)
for j in range(i):→range(1)→j = 0の1回だけ走る- 計算:
C[i+1][j+1] = C[i][j] + C[i][j+1] - ここでは
i+1 = 2,j+1 = 1→C[2][1] = C[1][0] + C[1][1] = 1 + 1 = 2 C[2]は[1, 2, 1]に更新される
- 計算:
- i=1 終了後の C:
[[1], [1, 1], [1, 2, 1]]
i = 2 のとき
- 開始時の C:
[[1], [1,1], [1,2,1]]
C.append([1] + [0]*2 + [1])→[1, 0, 0, 1]を追加 →C[3] = [1,0,0,1]for j in range(2):→j = 0, 1j = 0:C[3][1] = C[2][0] + C[2][1] = 1 + 2 = 3- 今
C[3]は[1, 3, 0, 1]
j = 1:C[3][2] = C[2][1] + C[2][2] = 2 + 1 = 3- 今
C[3]は[1, 3, 3, 1]
- i=2 終了後の C:
[[1], [1, 1], [1, 2, 1], [1, 3, 3, 1]]
i = 3 のとき
- 開始時の C: 上の状態(
C[3] = [1,3,3,1])
C.append([1] + [0]*3 + [1])→[1,0,0,0,1]を追加 →C[4] = [1,0,0,0,1]for j in range(3):→j = 0,1,2j=0:C[4][1] = C[3][0] + C[3][1] = 1 + 3 = 4j=1:C[4][2] = C[3][1] + C[3][2] = 3 + 3 = 6j=2:C[4][3] = C[3][2] + C[3][3] = 3 + 1 = 4
- i=3 終了後の C:
[[1], [1, 1], [1, 2, 1], [1, 3, 3, 1], [1, 4, 6, 4, 1]]
まとめ(一般形)
- 各イテレーション
iで行われていること:- 新しい行(長さ
i+2)を[1, 0, 0, ..., 0, 1]で作ってCに追加(これがC[i+1]になる)。 - 内側ループ
for j in range(i):により、j = 0 .. i-1の範囲でC[i+1][j+1] = C[i][j] + C[i][j+1]を計算して中身を埋める。 - 両端(インデックス
0とi+1)は最初から1なので変えない。
- 新しい行(長さ
- 数学的には
C[n][k] = C[n-1][k-1] + C[n-1][k](0 ≤ k ≤ n)を順に適用しているだけです。
⇒やっと大体理解できました。
・append([a]+[b]+[C])でリストに[a,b,c]を追加する。
・リストの掛け算はリストの個数を示す。 例)[0]*2=[0]+[0]
・C[i+1][j+1] = C[i][j] + C[i][j+1]はC[i+1][j+1]に該当するリストの具体的な数を、
C[i][j] + C[i][j+1]に書き換え

⇒以下の解答を作成したが間違い。典型的なミス。range(2)だとi=0、1まで。range(3)に修正したら正解。
def sum_matrix(list1, list2):
list3 = [[0,0,0],[0,0,0],[0,0,0]]
for i in range(2):
for j in range(2):
list3[i][j] = list1[i][j] + list2[i][j]
return list3
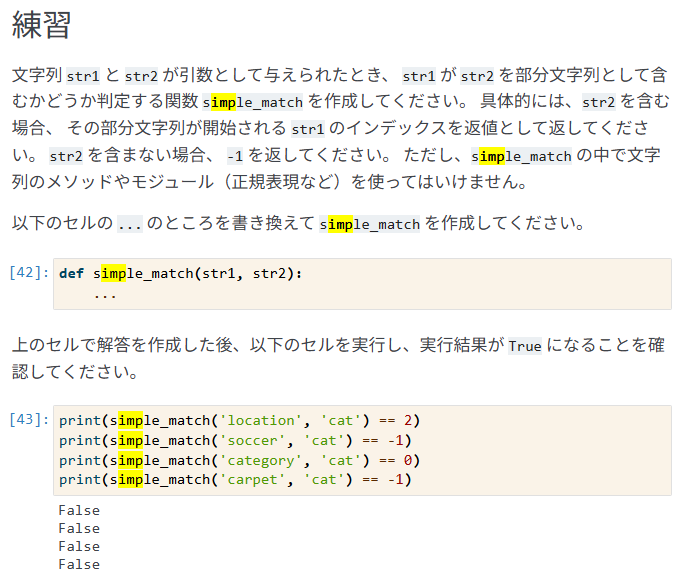
⇒以下の解答を作成したが間違い。「if str2 in str1:」の時点で、内部的にfindのようなメソッドを使っている。繰り返しが止まる位置は「最後に str2 が含まれなくなった位置」で、最初の一致位置ではない(同じ文字列が2回出てくる場合に間違いとなる)。
if str2 in str1:
x =0
while x > 0:
if str2 in str1[x:]:
x +=1
else:
break
return x-1
else:
return -1
⇒次の解答で正解
def simple_match(str1, str2):
for x in range(len(str1)-len(str2)+1):
if str2 == str1[x:x+len(str2)]:
return x
else:
return -1
x = -1
if x < 0:
print('x is positive')
elif x == 0:
# no error
pass
elif 0 < x < 5:
print('x is positive and smaller than 5')
else:
print('x is positive and larger than or equal to 5')
⇒内容とは関係ないが、’x is negative’では?
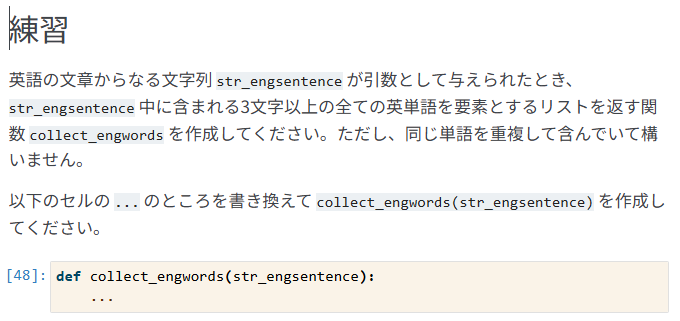
⇒以下の解答を作成したが間違い。ChatGPTによると以下の指摘。
① replace の結果を受け取っていない。
② [:index-1] だと最後の1文字が欠ける。スライスは後半の数字の1文字前までを疲労から[:index]でよい。
③ 最後の単語で index() がエラーになる。文末が「.」
def collect_engwords(str_engsentence):
list = []
str_engsentence.replace(‘ ‘, ‘,’)
while len(str_engsentence) > 0:
index = str_engsentence.index(‘,’)
strx = str_engsentence[:index-1]
str_engsentence = str_engsentence[index+1:]
if len(strx) > 2 :
list.append(strx)
return list
⇒以下に修正したところ正解。いきなり難しくないですか。
def collect_engwords(str_engsentence):
list = []
str_engsentence = str_engsentence.replace(‘ ‘, ‘,’)
str_engsentence = str_engsentence.replace(‘.’, ‘,’)
while len(str_engsentence) > 0:
index = str_engsentence.index(‘,’)
strx = str_engsentence[:index]
str_engsentence = str_engsentence[index+1:]
if len(strx) > 2 :
list.append(strx)
return list
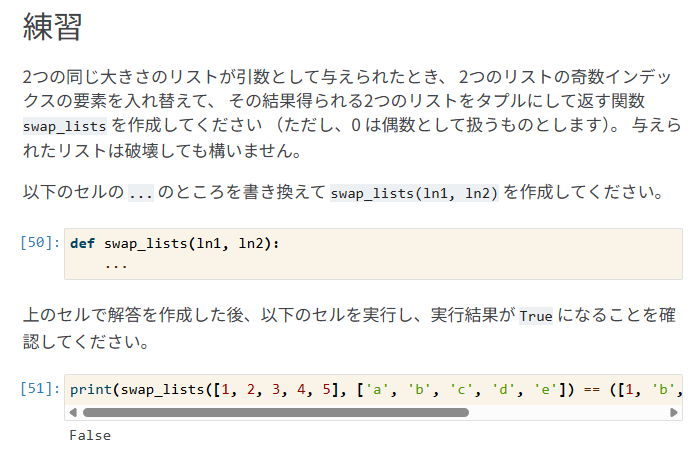
⇒以下の解答を作成したが間違い。ChatGPTによると以下の指摘。
def swap_lists(ln1, ln2):
list1 = []
list2 = []
if len(ln1) >= len(ln2):
for x in range(len(ln2)/2):
list1.append(ln1[2x])
list2.append(ln2[2x])
list1.append(ln2[2x+1])
list2.append(ln1[2x+1])
else x in range(len(ln1)/2):
list1.append(ln1[2x])
list2.append(ln2[2x])
list1.append(ln2[2x+1])
list2.append(ln1[2x+1])
tuple = (list1, list2)
return tuple
① 2x という書き方は Python ではエラー。正しくは:ln1[2*x]
② range(len(ln2)/2) はエラー(/ は float)。正しくは:range(len(ln2)//2)
③else x は Python の構文として成り立たない。そもそもこの問題は「2つのリストは同じ大きさ」
④list1, list2 を作り直している(破壊しても良いのにコピーしてる)
⑤tuple は組み込み型であり、変数名ではない
⑥そもそも “swap” の意味が違ってる。index = 1,3,5,… の要素を swap するだけ。
⇒①は忘れてた。納得。②も納得。少数の場合、rangeはどう処理されるんだろう、とは思っていた。③も納得。問題読み間違い。④は納得できない。破壊しても良いは破壊しなくても良いってことでは。
⑤は良く分からない。ダメなのか? ⑥も大きなお世話。交換する感じでコマンド書けたらこんな面倒な式は立てない。
以下に修正して一応true。
def swap_lists(ln1, ln2):
list1 = []
list2 = []
if len(ln1) % 2 ==0:
for x in range(len(ln1)//2):
list1.append(ln1[2x])
list2.append(ln2[2x])
list1.append(ln2[2x+1])
list2.append(ln1[2x+1])
else:
for x in range(len(ln1)//2):
list1.append(ln1[2x])
list2.append(ln2[2x])
list1.append(ln2[2x+1])
list2.append(ln1[2x+1])
list1.append(ln1[-1])
list2.append(ln2[-1])
tuple = (list1, list2)
return tuple
模範解答は以下の通り。こんな簡単に行けるとは。
・return ln1, ln2 はタプルらしい。(ln1, ln2)と同じ意味
・ln1[j], ln2[j] = ln2[j], ln1[j]は同時代入。こんなの習ったっけ?←2.2リストで多重代入という話があった。
ln1[j] = ln2[j]の後に、
ln2[j] = ln1[j]をやるのとは異なる。


⇒ 以下の解答を作ったら正解。 珍しくすんなり解けた。
def count_capitalletters(str1):
CAPITALS = ‘ABCDEFGHIJKLMNOPQRSTUVWXYZ’
sum = 0
for x in CAPITALS:
sum += str1.count(x)
return sum
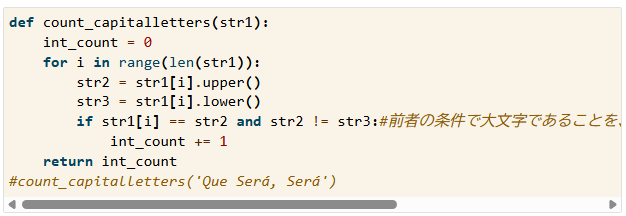
模範解答は以下の通り。私の回答の方がシンプルかも。str2 != str3で記号を除外。
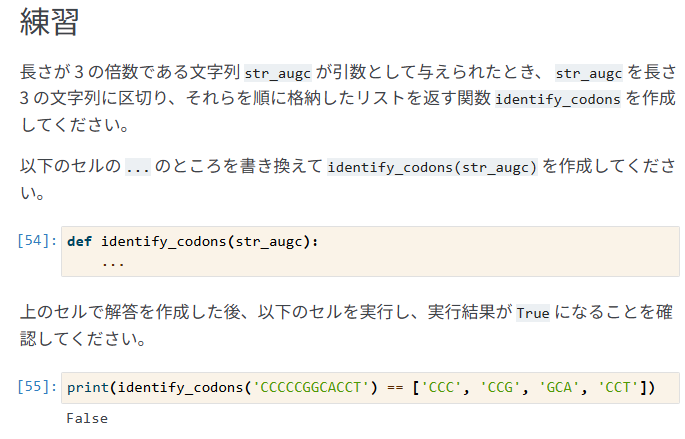
⇒ 以下の解答を作ったら正解。スライスをx+2にしないように注意。
def identify_codons(str_augc):
list = []
for x in range(0,len(str_augc),3):
list.append(str_augc[x:x+3])
return list
模範解答は以下の通り。rangeの置き方が違うくらい。

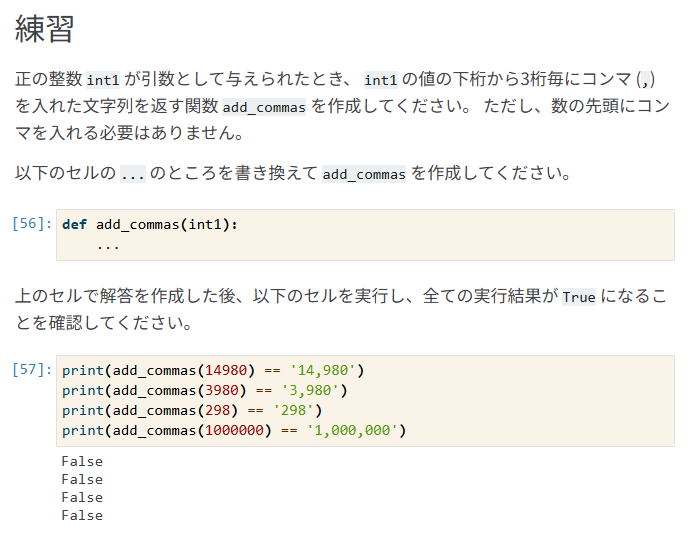
⇒以下の解答を作成したところ正解。whileを使う時はx=1とx += 1の併用が分かりやすい。len(word)はコンマでwordの長さが変わるから、「-x」を入れている。また、whileの終点も変わると面倒なので、最初に定数tにした。
def add_commas(int1):
word = str(int1)
t = len(word)
x = 1
while 3x < t:
word = word[:len(word)-3x+1-x]+’,’+word[len(word)-3*x-x+1:]
x += 1
return word
模範解答は以下の通り。rangeの3番目を-1にすることで後ろから処理できるとは思いつかなかった。

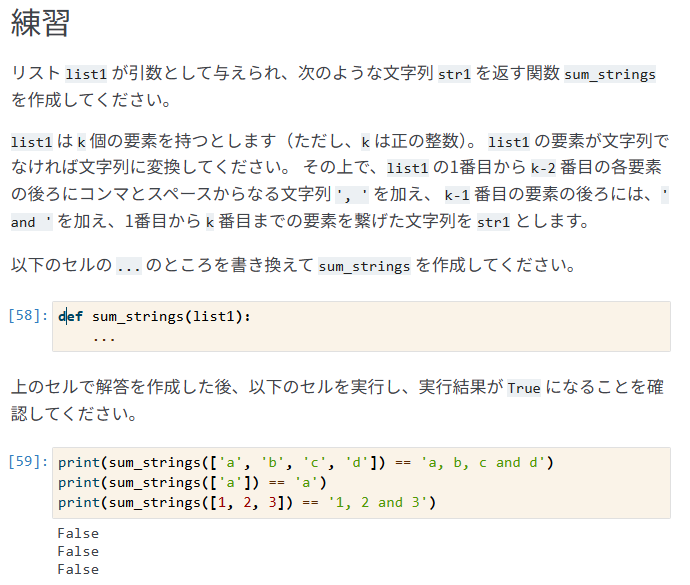
⇒以下の解答を作成したが間違い。「list1 の要素が文字列でなければ文字列に変換する」という内容に対処できていない。文字列じゃない場合に間違いになる。
def sum_strings(list1):
t = len(list1[-1])+2
str0 = ‘, ‘.join(list1)
if ‘,’ in str0:
str1 = str0[:-t] + ” and” + str0[-t+2:]
else:
str1 = str0
return str1
⇒以下の回答にして正解。len(リスト)でリストの要素の数を数えられる。ifのところは「=」ではなく「==」。「=」だと定義になってしまう。
def sum_strings(list1):
if len(list1) ==1:
str1= str(list1[0])
elif len(list1) == 2:
str1= str(list1[0]) + ‘ and ‘ + str(list1[1])
else:
t = 1
str1= str(list1[0])
while t < len(list1)-1:
str1 = str1 + ‘, ‘ + str(list1[t])
t +=1
str1 = str1 + ‘ and ‘ + str(list1[-1])
return str1
以下が模範解答。模範解答の方が簡潔。


⇒以下の回答にして正解。
def handle_collision2(dic1, str1):
if len(dic1) == 10: #dic1が全て埋まっている時は即終了
return dic1
else:
n = len(str1)
while n >0:
if n not in dic1: #nがキーの数字として無かったら、そこでストップ
break
elif n < 10: #あったらn に1追加
n += 1
else:
n = 1
dic1[n] = str1
return dic1
以下が模範解答。まずgetメソッドを忘れていた。rangeでiにnから順番に11の前(10)まで入れる。return dic1にしなくて良いのか?←dic1 は参照渡しなので変更が反映される、とのこと(ChatGPT)。それ自体を変更する場合はreturnが不要で、新しく作る場合は必要って話だと理解。


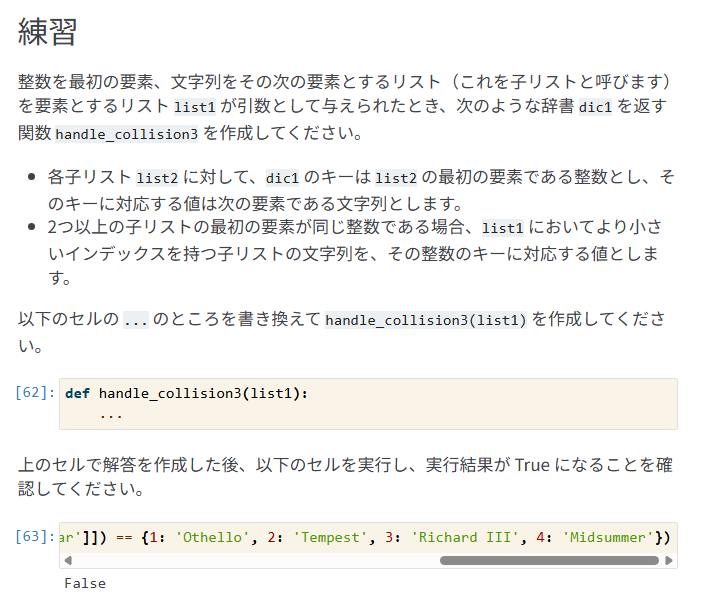
以下の回答で正解。すぐできた。
def handle_collision3(list1):
dic1 = {}
n = 0
while n < len(list1):
if list1[n][0] not in dic1:
dic1[list1[n][0]] = list1[n][1]
n += 1
else:
n += 1
return dic1
以下が模範解答。
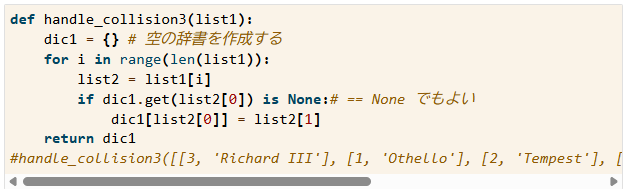

コメント